|
I am a teaching professor in the Department of Computer Science at Princeton University, where I teach intro and AIML CS courses and conduct research in computer vision and machine learning with a focus on explainable AI. At Princeton, I lead the Looking Glass Lab and frequently collaborate with Professor Olga Russakovsky and the Visual AI Lab. I completed my PhD in the Visual Geometry Group at the University of Oxford, where I was advised by Andrea Vedaldi and funded by the Rhodes Trust and Open Philanthropy. Also at Oxford, I earned a Masters in Neuroscience, where I worked with Rafal Bogacz, Ben Willmore, and Nicol Harper. I received a Bachelors in Computer Science at Harvard University, where I worked with David Cox and Walter Scheirer. Funding acknowledgements: Looking Glass Lab is grateful to Princeton SEAS and Open Philanthropy for generous support of our research.
Email | CV | Bio | Google Scholar | GitHub |

|
|
COS324. I'm excited to have you in my class this semester! Please see Canvas for the best ways to reach the course staff. Research/IW/thesis advising. I enjoy working with Princeton students! Unfortunately, I am not accepting with new students this academic year (2023-2024). As such, there's no need to email me about research/IW/thesis opportunities.
Other Princeton things. Engaging with students is one of my favorite parts of the job. If you'd like to reach me about other Princeton-related things (e.g. participating in a student event), shoot me an email! |
|
|
Members
Collaborators
Awards
Alumni
|
|
My research interests are in computer vision, machine learning (ML), and human-computer interaction (HCI), with a particular focus on explainable AI and ML fairness. Most of my work focuses on developing novel techniques for understanding AI models post-hoc, designing new AI models that are interpretable-by-design, and/or introducing paradigms for finding and correcting existing failure points in AI models. See Google Scholar for the most updated list of papers. * denotes equal contribution; ^ denotes peer-reviewed, non-archival work (e.g. accepted to non-archival workshop). |
 Adam Kelch
Adam Kelch
 Sai Rachumalla
Sai Rachumalla
 Indu Panigrahi
Indu Panigrahi
 Nicole Meister
Nicole Meister
 Dora Zhao
Dora Zhao
 Sunnie S. Y. Kim
Sunnie S. Y. Kim
 Ryan Manzuk
Ryan Manzuk
 Vikram V. Ramaswamy
Vikram V. Ramaswamy
 Angelina Wang
Angelina Wang
 Dr. Elizabeth Anne Watkins
Dr. Elizabeth Anne Watkins
 Prof. Olga Russakovsky
Prof. Olga Russakovsky
 Prof. Andrés Monroy-Hernández
Prof. Andrés Monroy-Hernández
 Prof. Adam C. Maloof
Prof. Adam C. Maloof

|
Sunnie S. Y. Kim, Elizabeth Anne Watkins, Olga Russakovsky, Ruth Fong, Andrés Monroy-Hernández FAccT, 2023 arXiv | project page | bibtex We study how end-users trust AI in a real-world context. Concretely, we describe multiple aspects of trust in AI and how human, AI, and context-related factors influence each.
|
|
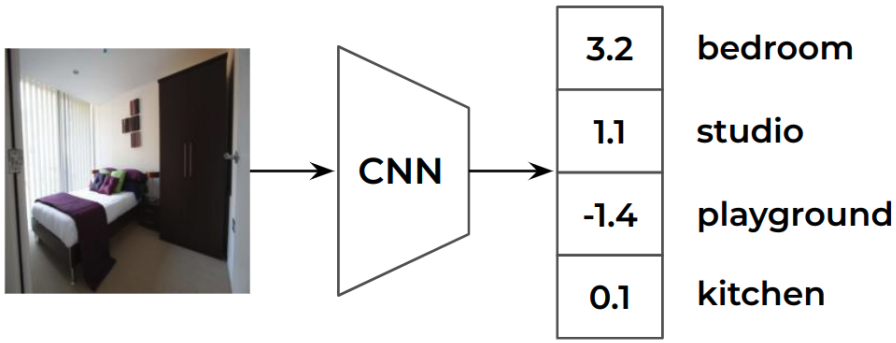
Vikram V. Ramaswamy, Sunnie S. Y. Kim, Ruth Fong, Olga Russakovsky arXiv, 2023 arXiv | bibtex We introduce a novel concept-based explanation framework for CNNs: UFO, which is a method for controlling the understandability and faithfulness of concept-based explanations using well-defined objective functions for the two qualities. |

|
Indu Panigrahi, Ryan Manzuk, Adam Maloof, Ruth Fong CVPR Workshop on Learning with Limited Labelled Data for Image and Video Understanding, 2023 arXiv | bibtex We explore how to improve a model for segmenting coral reef fossils by first understanding its systematic failures and second ``editing'' the model to mitigate said failures. |
|
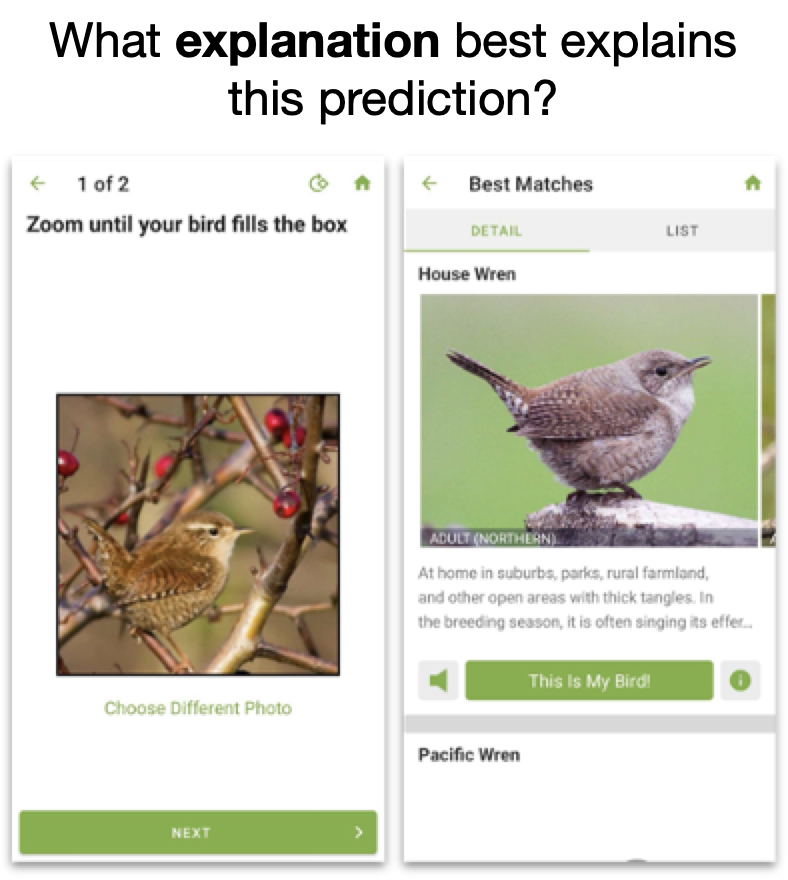
Sunnie S. Y. Kim, Elizabeth Anne Watkins, Olga Russakovsky, Ruth Fong, Andrés Monroy-Hernández CHI, 2023 (Honorable Mention award 🏆) arXiv | supp | 30-sec video | 10-min video | bibtex We explore how explainability can support human-AI interaction by interviewing 20 end-users of a real-world AI application. Specifically, we study (1) what XAI needs people have, (2) how people intend to use XAI explanations, and (3) how people perceive existing XAI methods.
|
|
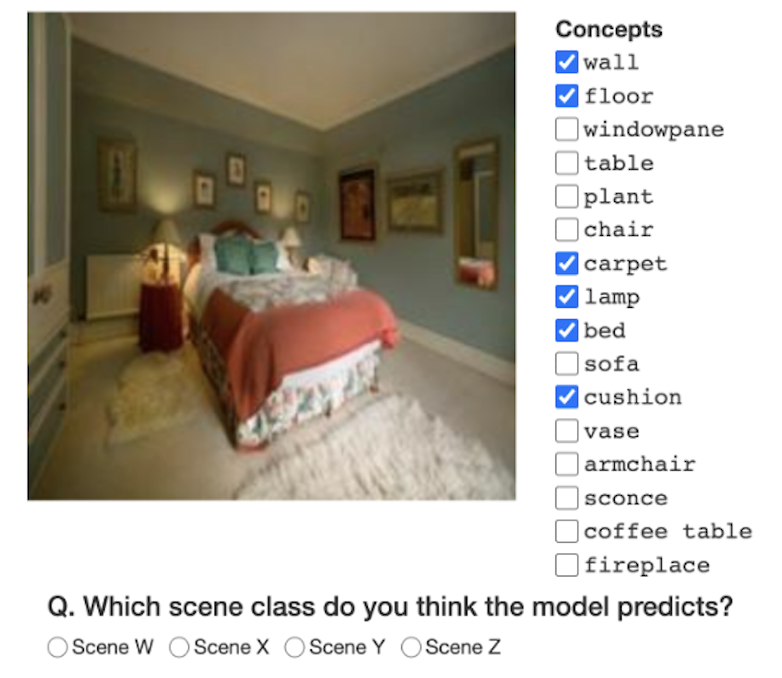
Vikram V. Ramaswamy, Sunnie S. Y. Kim, Ruth Fong, Olga Russakovsky CVPR, 2023 arXiv | bibtex We analyze three commonly overlooked factors in concept-based explanations, (1) the choice of the probe dataset, (2) the saliency of concepts in the probe dataset, (3) the number of concepts used in explanations, and make suggestions for future development and analysis of concept-based interpretability methods. |


|
Devon Ulrich and Ruth Fong NeurIPS Workshop on XAI in Action: Past, Present, and Future Applications, 2023 arXiv | code | bibtex We present an interactive visualization tool that allows you to perform a reverse image search for similar image regions using intermediate activations. |
|
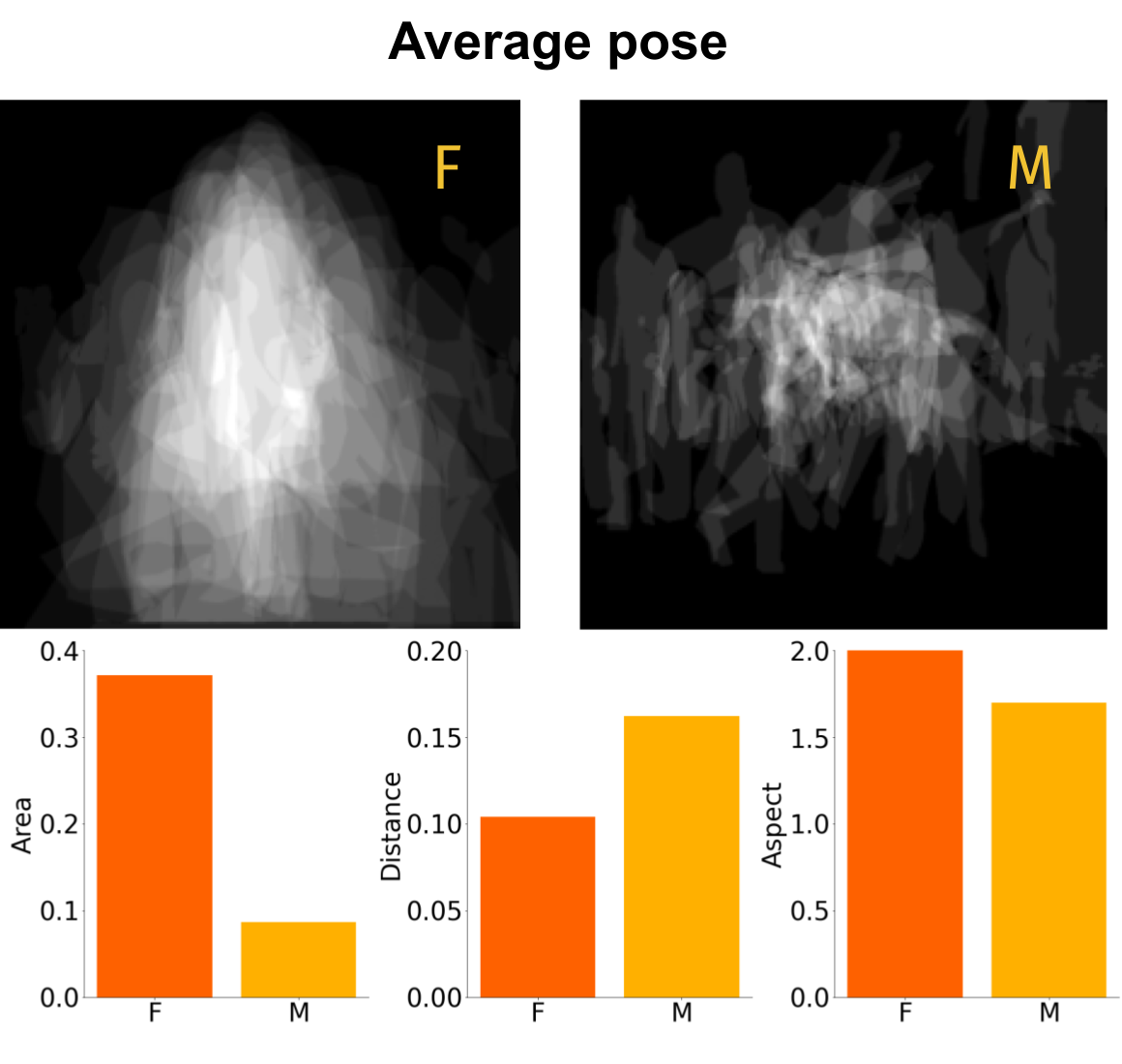
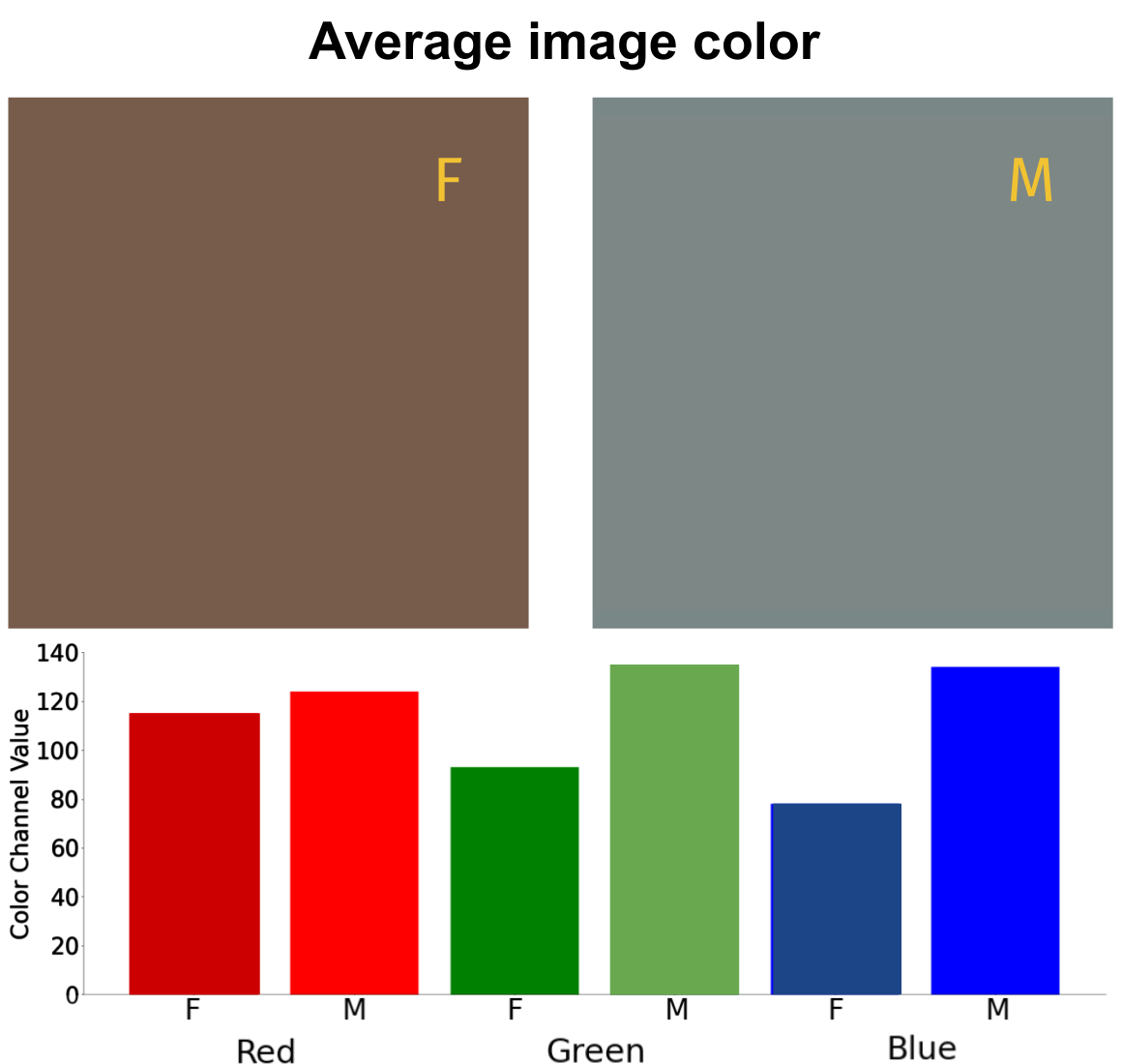
Nicole Meister*, Dora Zhao*, Angelina Wang, Vikram V. Ramaswamy, Ruth Fong, Olga Russakovsky ICCV, 2023 arXiv | project page | bibtex We demonstrate the pervasive-ness of gender artifacts in popular computer vision datasets (e.g. COCO and OpenImages). We find that all of the following (and more) are gender artifacts: the mean value of color channels (i.e. mean RGB), the pose and location of people, and most co-located objects. |

|
Vikram V. Ramaswamy, Sunnie S. Y. Kim, Nicole Meister, Ruth Fong, Olga Russakovsky arXiv, 2022 arXiv | bibtex We present ELUDE, a novel explanation framework that decomposes a model's prediction into two components: 1. using labelled, semantic attributes (e.g. fur, paw, etc.) and 2. using an unlabelled, low-rank feature space. |

|
Sunnie S. Y. Kim, Nicole Meister, Vikram V. Ramaswamy, Ruth Fong, Olga Russakovsky ECCV, 2022 arXiv | project page | extended abstract | code | 2-min video | bibtex We introduce HIVE, a novel human evaluation framework for diverse interpretability methods in computer vision, and develop metrics that measure achievement on two desiderata for explanations used to assist human decision making: (1) Explanations should allow users to distinguish between correct and incorrect predictions. (2) Explanations should be understandable to users. |


|
Ruth Fong, Alexander Mordvintsev, Andrea Vedaldi, Chris Olah VISxAI, 2021 interactive article | code | bibtex We introduce a novel interactive visualization that allows machine learning practitioners and researchers to easily observe, explore, and compare how a neural network perceives different image regions. |
|
Mandela Patrick*, Yuki M. Asano*, Polina Kuznetsova, Ruth Fong, João F. Henriques, Geoffrey Zweig, and Andrea Vedaldi ICCV, 2021 arXiv | code | bibtex We give transformations the prominence they deserve by introducing a systematic framework suitable for contrastive learning. SOTA video representation learning by learning (in)variances systematically. |


|
Iro Laina, Ruth Fong, and Andrea Vedaldi NeurIPS, 2020 arxiv | supp | bibtex We introduce two novel human evaluation metrics for quantifying for evaluating the interpretability of clusters discovered via self-supervised methods. We also outline how to partially approximate one of the metrics using a group captioning model. |
|
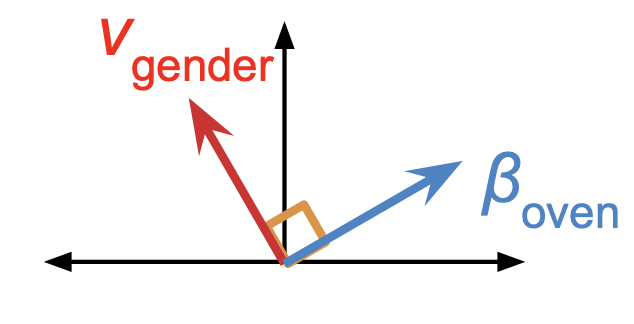
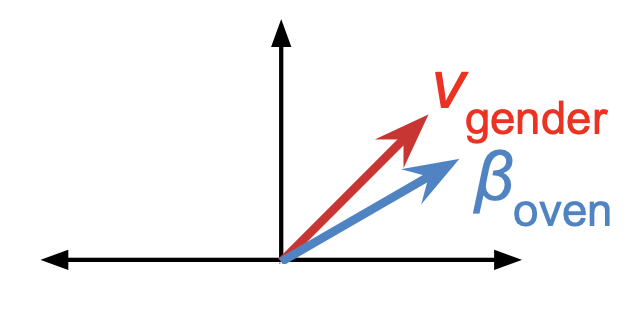
Kurtis Evan David, Qiang Liu, and Ruth Fong NeurIPS Workshop on Algorithmic Fairness through the Lens of Causality and Interpretability (AFCI), 2020 arxiv | supp | poster | bibtex We introduce a novel paradigm for debiasing CNNs by encouraging salient concept vectors to orthogonal to class vectors in the activation space of an intermediate CNN layer (e.g., orthogonalizing gender and oven concepts in conv5). |
|
Diego Marcos, Ruth Fong, Sylvain Lobry, Rémi Flamary, Nicolas Courty, and Devis Tuia ACCV, 2020 arxiv | supp | code | bibtex We introduce an interpretable-by-design machine vision model that learns to sparse groupings of interpretable concepts and demonstrate the utility of our novel architecture on scenicness prediction. |
|
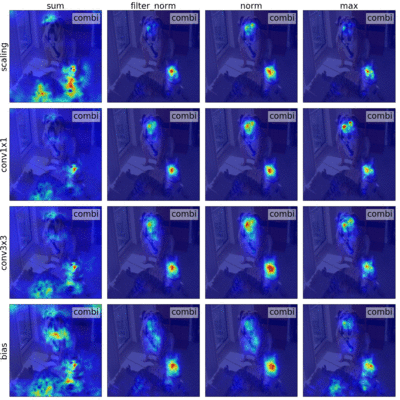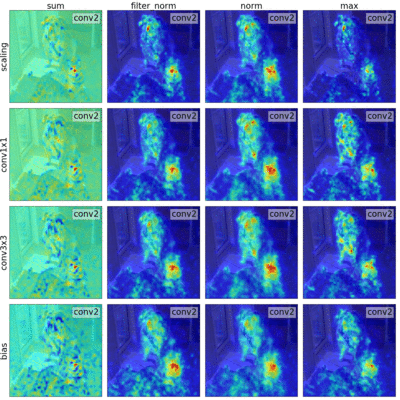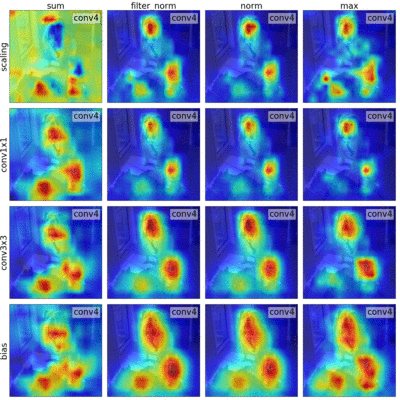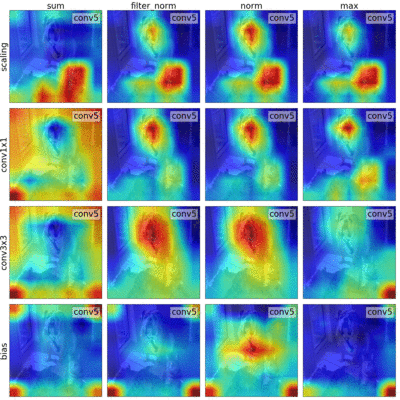
Sylvestre-Alvise Rebuffi*, Ruth Fong*, Xu Ji*, and Andrea Vedaldi CVPR, 2020 arxiv | code | bibtex We outline a novel framework that unifies many backpropagation saliency methods. Furthermore, we introduce NormGrad, a saliency method that considers the spatial contribution of the gradients of convolutional weights. We also systematically study the effects of combining saliency maps at different layers. Finally, we introduce a class-sensitivity metric and a meta-learning inspired technique that can be applied to any saliency method to improve class sensitivity. |

|
Miles Brundage*, Shahar Avin*, Jasmine Wang*, Haydn Belfield*, Gretchen Krueger*, … , Ruth Fong, et al. arXiv, 2020 arxiv | project page | bibtex This report suggests various steps that different stakeholders can take to make it easier to verify claims made about AI systems and their associated development processes. The authors believe the implementation of such mechanisms can help make progress on one component of the multifaceted problem of ensuring that AI development is conducted in a trustworthy fashion. |
 
|
Ruth Fong*, Mandela Patrick*, and Andrea Vedaldi ICCV, 2019 (Oral) arxiv | supp | poster | code (TorchRay) | 4-min video | bibtex We introduce extremal perturbations, an novel attribution method that highlights "where" a model is "looking." We improve upon Fong and Vedaldi, 2017 by separating out regularization on the size and smoothness of a perturbation mask from the attribution objective of learning a mask that maximally affects a model's output; we also extend our work to intermediate channel representations. |
 
|
Ruth Fong and Andrea Vedaldi ICCV Workshop on Interpreting and Explaining Visual Artificial Intelligence Models, 2019 paper | bibtex | code (coming soon) We introduce a simple paradigm based on batch augmentation for leveraging input-level occlusions (both stochastic and saliency-based) to improve ImageNet image classification. We also demonstrate the necessary of batch augmentation and quantify the robustness of different CNN architectures to occlusion via ablation studies. |
 
|
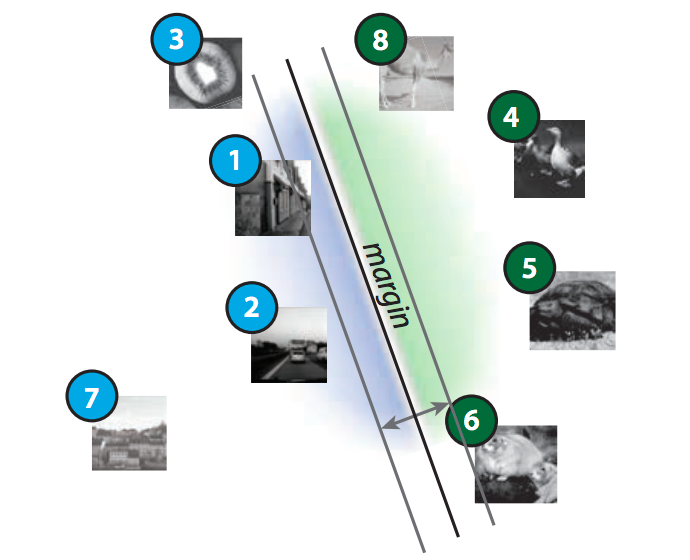
Ruth Fong and Andrea Vedaldi CVPR, 2018 (Spotlight) arxiv | supp | bibtex | code | 4-min video | slides Investigating how human-interpretable visual concepts (i.e., textures, objects, etc.) are encoded across hidden units of a convolutional neural network (CNN) layer as well as across CNN layers. |
|
We introduce a biologically-informed machine learning paradigm for object classification that biases models to better match the learned, internal representations of the visual cortex. |
  |
Ruth Fong and Andrea Vedaldi ICCV, 2017 arxiv | supp | bibtex | code | book chapter (extended) | chapter bibtex We developed a theoretical framework for learning "explanations" of black box functions like CNNs as well as saliency methods for identifying "where" a computer vision algorithm is looking. |
|
|
|
|
This is a "thesis-by-staples", so the novel parts are the non-paper chapters (i.e. all chapters except chapters 3-6), which I wrote with accessibility in mind (e.g., the ideal reader is a motivated undergraduate or graduate student looking to learn more about deep learning and interpretability). The introduction is accessible to a high-school student, and appendices A and B are primers on the relevant math concepts and convolutional neural networks respectively. |
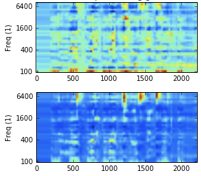  |
I developed an unsupervised learning paradigm for sound separation using fully connected and recurrent neural networks to predict the future from past cochleagram data. |
|
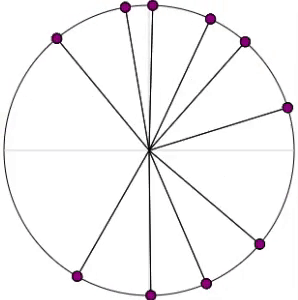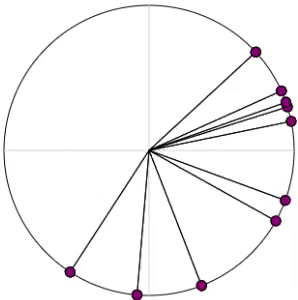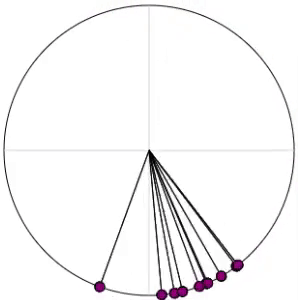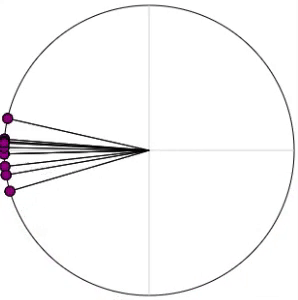
I developed a computational oscillator model that modeled the tremor-dampening effects of phasic deep brain stimulation and analyzed it on experimental data. |
|
|
Published as Fong et al., Scientific Reports 2018. |
|
|


|
This ubiquitous CS researcher website template spawned from here.
|